Introduction
At the heart of Newmetric's product is a high-performance RPC cluster that is capable of handling several thousands of requests per second. To achieve this goal, Newmetric employs a noble architectural pattern that is not commonly found in the blockchain space — Edge Computation.
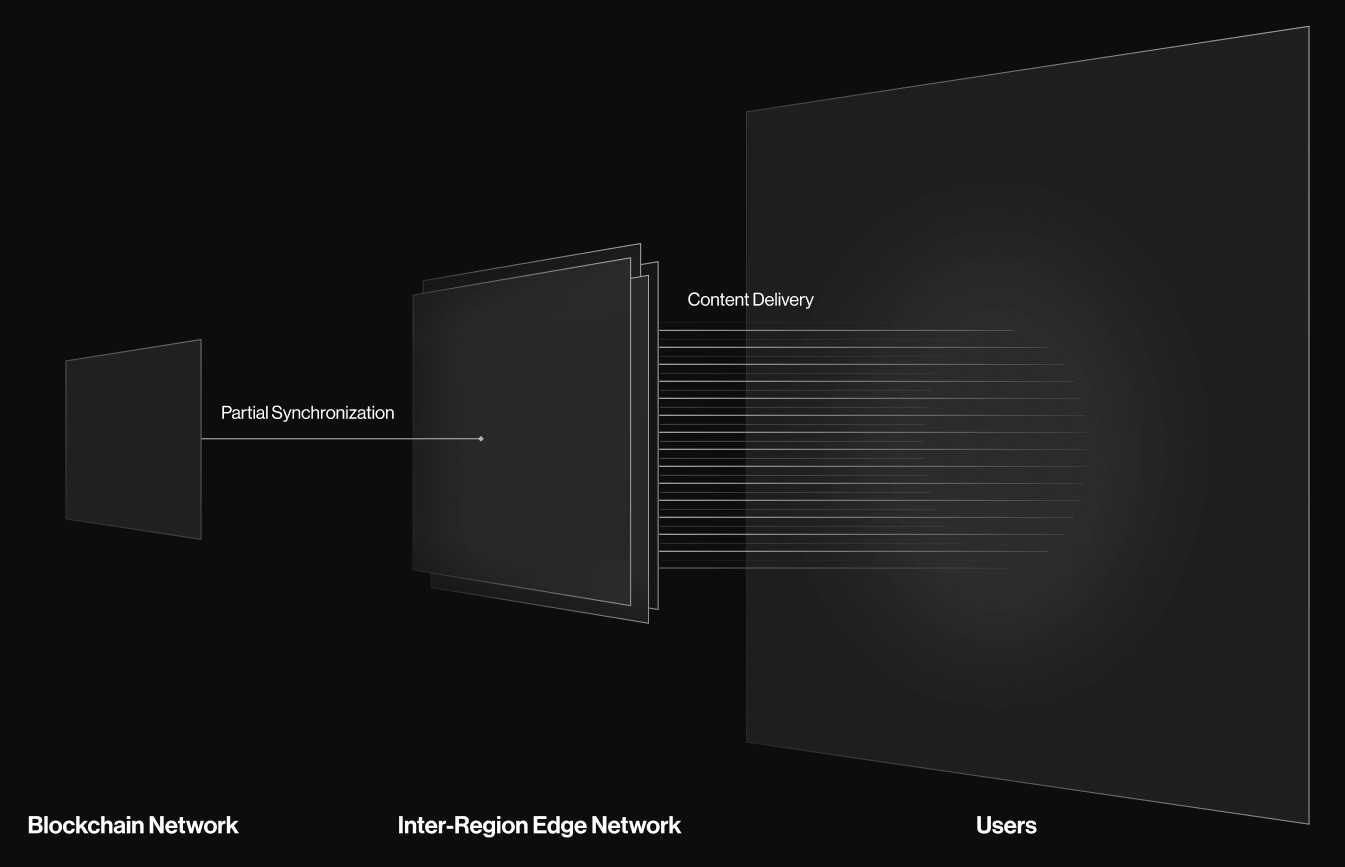
Edge Computation is a family of techniques that allow for the processing of requests in a computing node that is physically close to the end user. By moving the computing node and partial database closer to the end user, we can reduce the latency of the request, and improve the overall performance of the system.
Motivation
This architecture is a stark departure from the traditional blockchain client architecture. Generally speaking, scaling up RPC is done by spinning up many more nodes and depending on the underlying consensus protocol to achieve state replication. This is a costly and time-consuming process, and is not suitable for quickly scaling up/down, due to the time involved in provisioning storage, and the cost involved in replicating the entire state.
RPC is really just a web service
Our take is that blockchain RPC is not that different from a generic web service. From a high-level perspective, a web service is a passive state machine that computes some output from some data source. Scaling a web service usually involves horizontally scaling the server applications, along with the database via replicating/sharding, but kept just enough.
The same can be applied to blockchain clients. Technically speaking, blockchain RPC is a state machine (VM) that computes some output (RPC response), from some data source (blockchain state). As long as the underlying state is somehow shared across read-only nodes, the same scaling methods can be applied.
We probably don't need the entire state to serve RPC
The entire state of a blockchain is usually very large, and is growing at a rapid pace. It's usually in the range of tens of gigabytes, if not terabytes. Do we really need all of it? Do we really need to replicate the full storage to serve queries? What is the effective utilization of this big storage?
We believe that query pattern in practice strictly follows Zipf's law — a small number of queries are very popular, while the rest are not. For example, only small number (compared to the entire account set) of active users would send a transaction and eventually alter some state in the blockchain. These state updates are closely correlated to the type of actions (whether it be a transfer, a smart contract call, or a staking action), and the very address of the user, or some contracts that are popular.
According to our internal simulation, the storage utilization is only < 2% for a mature blockchain. This means as long as we somehow replicate only ~2% of the entire state, we can reliably serve most of the queries at times. This is a significant improvement in terms of size of bytes exchanged, over the traditional replicate-everything approach.
Based on this idea, our architecture is heavily based on partial replication. Only a subset of data, including the recent-most changes, are synchronized across the cluster. Read-only nodes then read from these intra-cluster database, and further cache them in an extremely fast in-memory storage — with a very high cache hit rate.
The goal
With this architecture, we aim to achieve the following goals:
- Elastic scalability, by scaling up/down EdgeNodes as needed.
- Cost efficiency, by only replicating a small subset of the entire state.
- Improved reliability, by separating roles of a typical blockchain client, allowing for a better recoverability and overall reliability.
Next steps
We are going to do a deep dive into the architecture, and explain how we achieve the above goals with each component in our architecture.